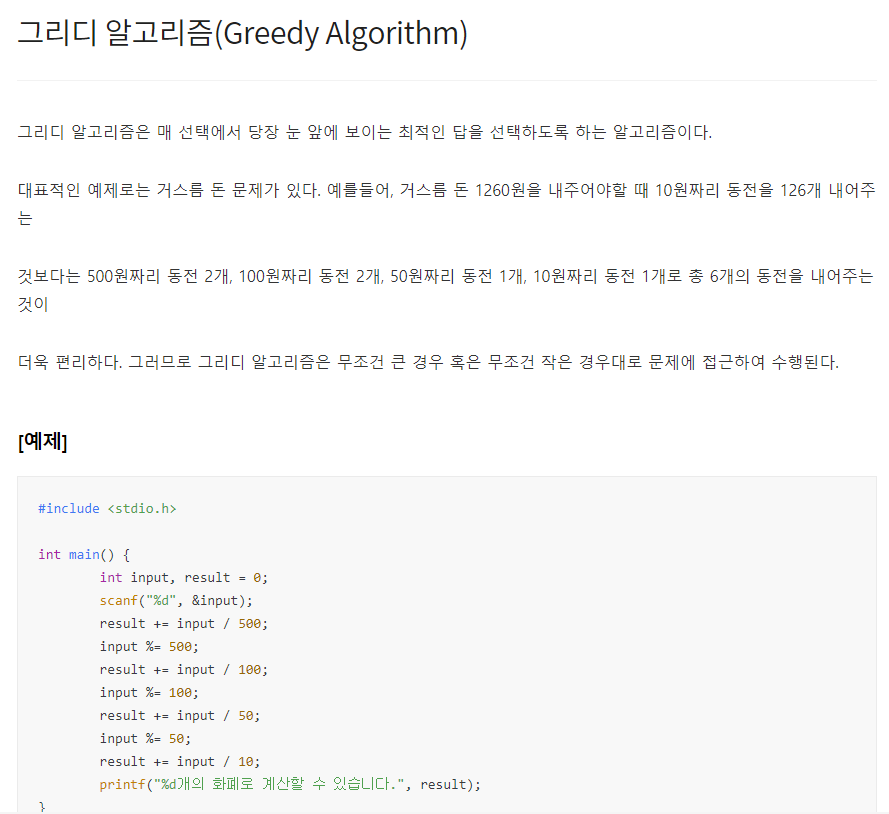
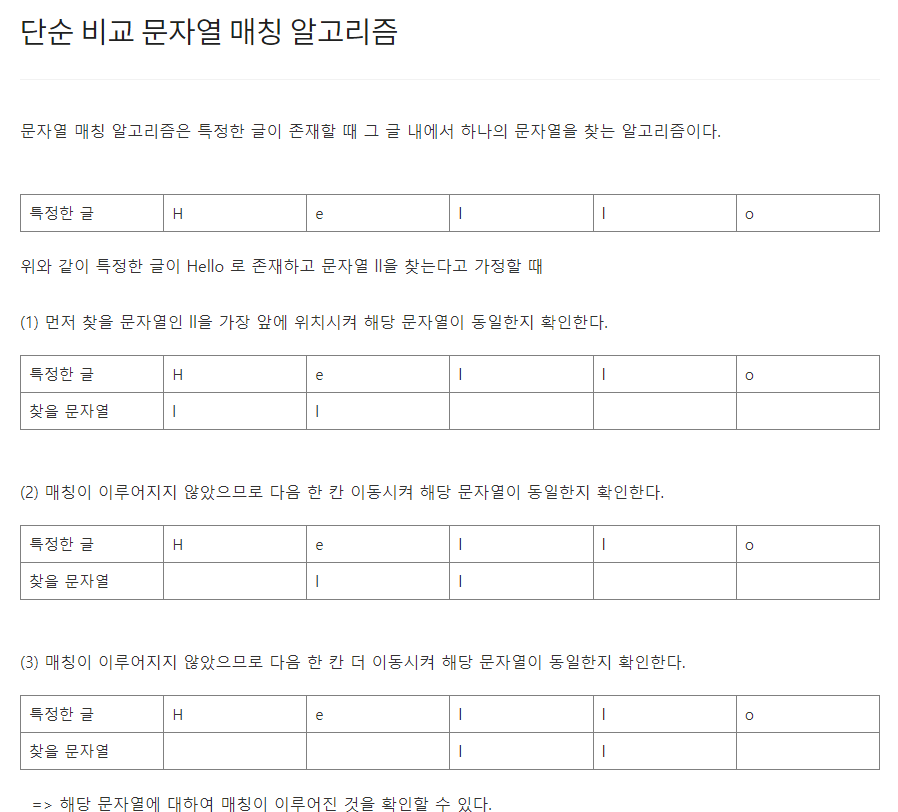
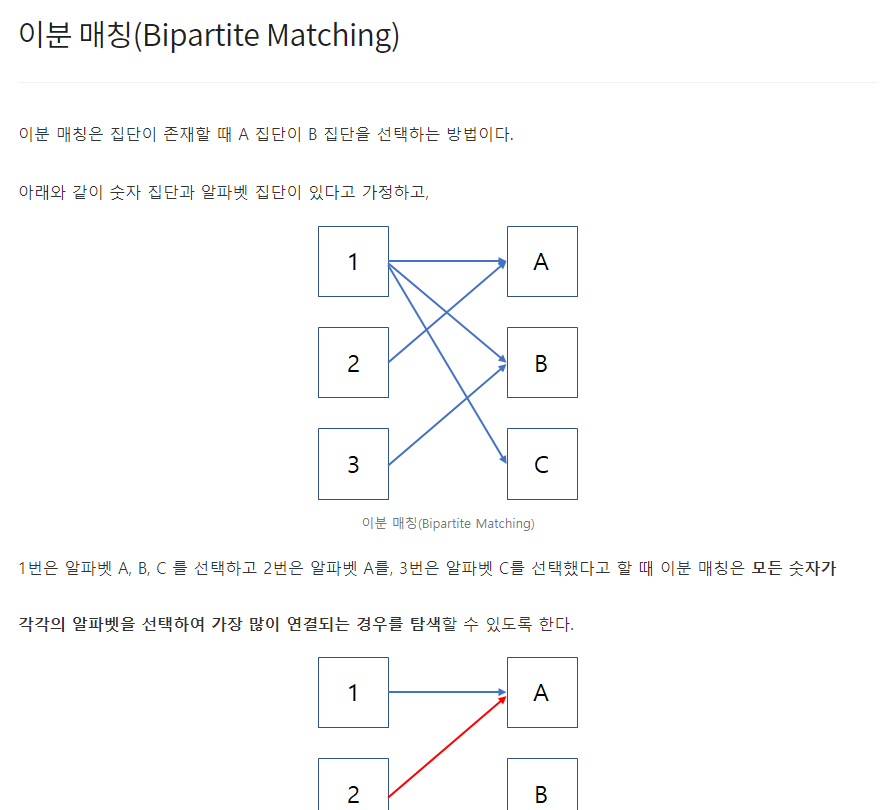
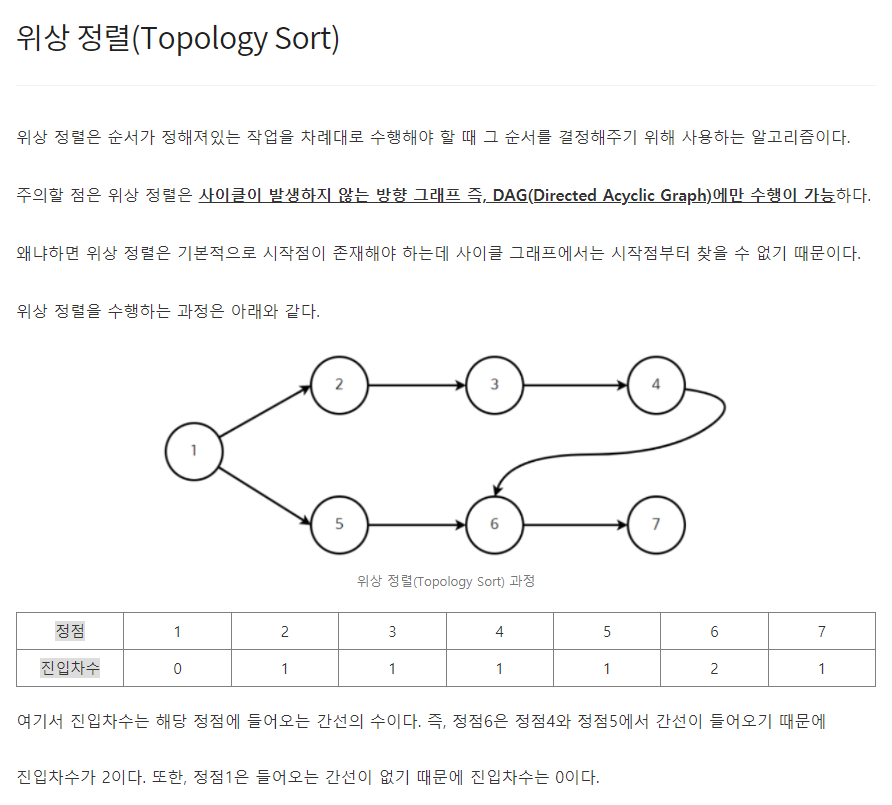
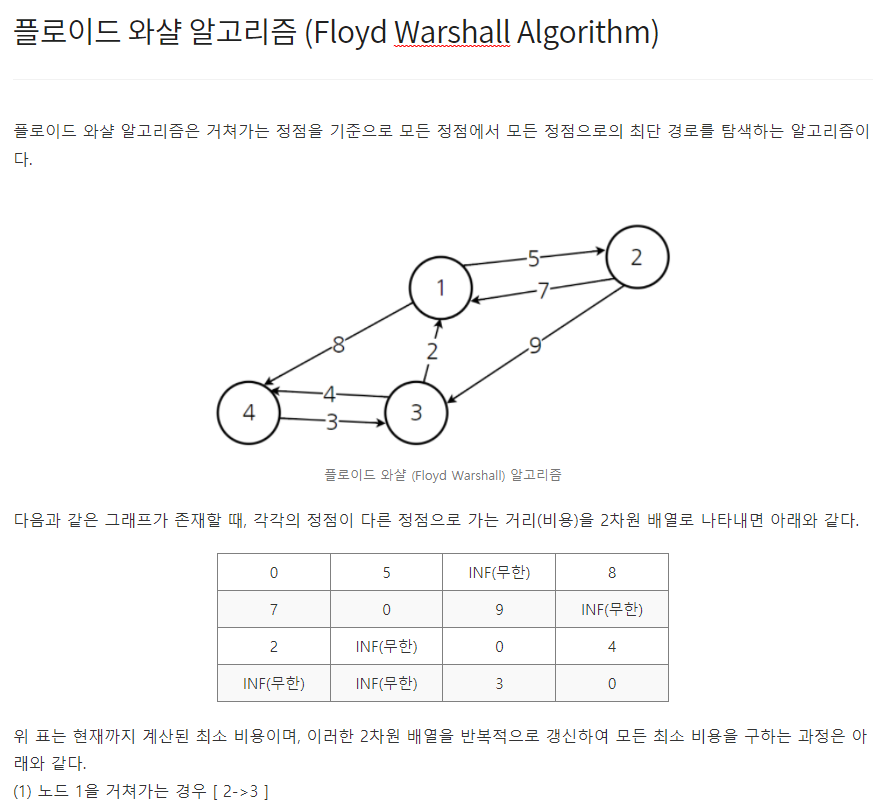
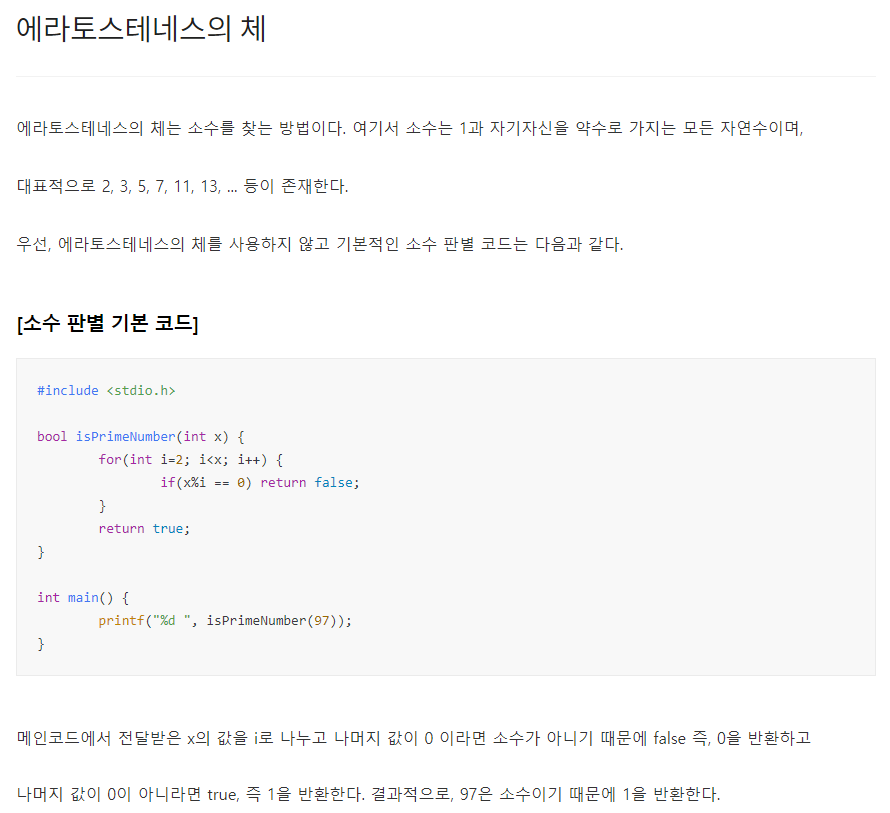
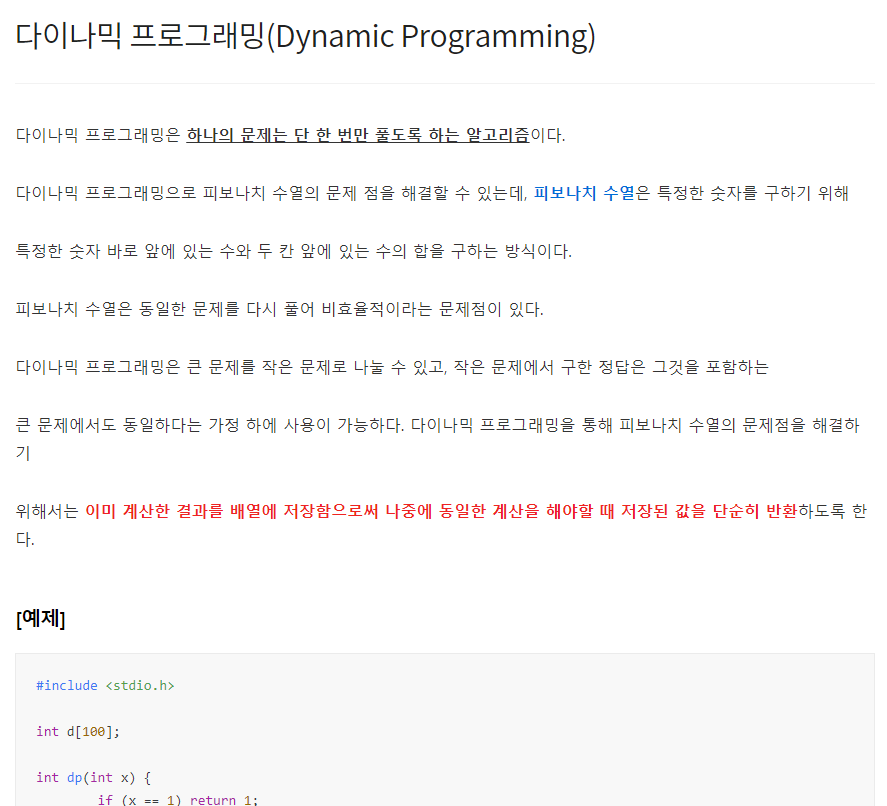
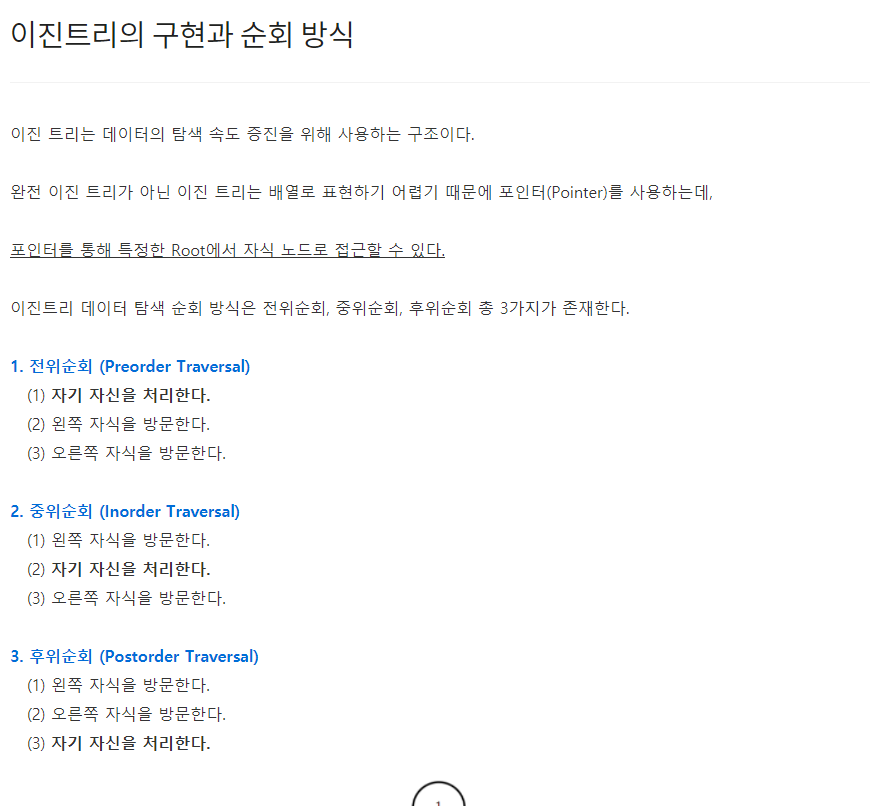
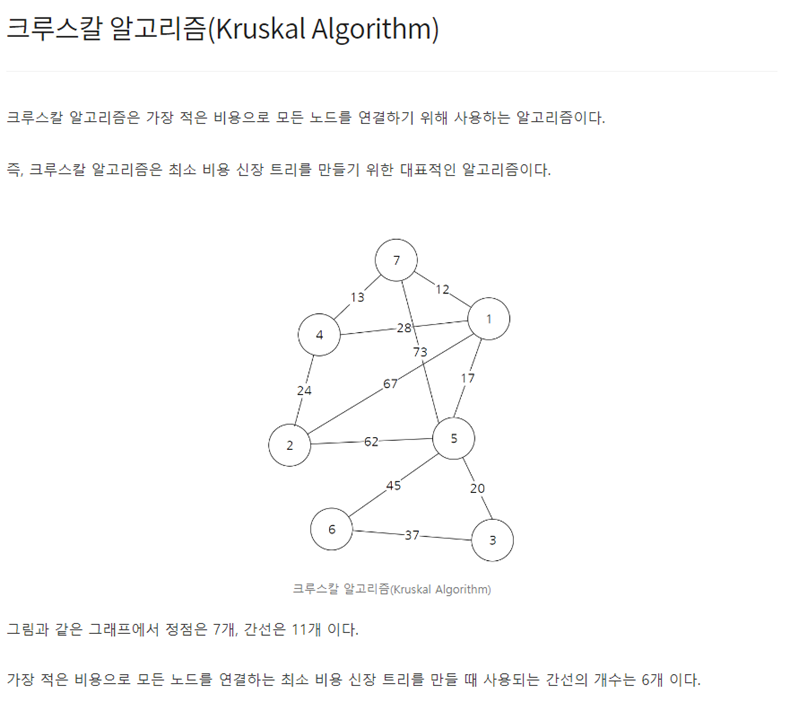
그리디 알고리즘은 매 선택에서 당장 눈 앞에 보이는 최적인 답을 선택하도록 하는 알고리즘이다. 대표적인 예제로는 거스름 돈 문제가 있다. 예를들어, 거스름 돈 1260원을 내주어야할 때 10원짜리 동전을 126개 내어주는 것보다는 500원짜리 동전 2개, 100원짜리 동전 2개, 50원짜리 동전 1개, 10원짜리 동전 1개로 총 6개의 동전을 내어주는 것이 더욱 편리하다. 그러므로 그리디 알고리즘은 무조건 큰 경우 혹은 무조건 작은 경우대로 문제에 접근하여 수행된다. [예제] #include int main() { int input, result = 0; scanf("%d", &input); result += input / 500; input %= 500; result += input / 100; inp..