문자열 매칭 알고리즘은 특정한 글이 존재할 때 그 글 내에서 하나의 문자열을 찾는 알고리즘이다.
| 특정한 글 | H | e | l | l | o |
위와 같이 특정한 글이 Hello 로 존재하고 문자열 ll을 찾는다고 가정할 때
(1) 먼저 찾을 문자열인 ll을 가장 앞에 위치시켜 해당 문자열이 동일한지 확인한다.
| 특정한 글 | H | e | l | l | o |
| 찾을 문자열 | l | l |
(2) 매칭이 이루어지지 않았으므로 다음 한 칸 이동시켜 해당 문자열이 동일한지 확인한다.
| 특정한 글 | H | e | l | l | o |
| 찾을 문자열 | l | l |
(3) 매칭이 이루어지지 않았으므로 다음 한 칸 더 이동시켜 해당 문자열이 동일한지 확인한다.
| 특정한 글 | H | e | l | l | o |
| 찾을 문자열 | l | l |
=> 해당 문자열에 대하여 매칭이 이루어진 것을 확인할 수 있다.
[예제]
#include <iostream>
using namespace std;
int findString(string parent, string pattern) {
int parentSize = parent.size();
int patternSize = pattern.size();
for(int i=0; i<=parentSize-patternSize; i++) {
bool finded = true;
for(int j=0; j<patternSize; j++) {
if(parent[i+j] != pattern[j]) {
finded = false;
break;
}
}
if(finded)
return i;
}
return -1;
}
int main() {
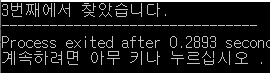
string parent = "Hello World";
string pattern = "llo W";
int result = findString(parent, pattern);
if(result == -1)
printf("해당 문자열을 찾을 수 없습니다.");
else
printf("%d번째에서 찾았습니다.", result +1);
}
해당 소스코드는 C++로 작성한 코드이다.
문자열 매칭 알고리즘 수행에 해당하는 findString() 함수 내의 첫번째 반복문에서 변수 finded 값을 true값으로 지정한다.
그 후 두번째 반복문을 통해 만약 문자열의 해당 위치와 찾을 문자열의 해당 위치 값이 다를 경우 finded 값을 false값으로
지정한 후 반복문을 빠져나와 -1을 반환한다.
그렇지 않고 해당 문자열이 같을 경우에는 해당 인덱스를 반환하도록 한다.
최종적으로 메인 코드에서 함수에서 리턴받은 값에 +1을 증가시켜 출력한다. 배열의 인덱스는 기본적으로 0부터 시작하기 때문이다.
[결과]
출처
https://blog.naver.com/ndb796/221240660061
30. KMP(Knuth-Morris-Pratt) 알고리즘
이번 시간에 다루게 될 알고리즘은 KMP 알고리즘으로 대표적인 문자열(String) 매칭 알고리즘입니다. ...
blog.naver.com
'알고리즘 > 나동빈 실전 알고리즘' 카테고리의 다른 글
| 그리디 알고리즘(Greedy Algorithm) (0) | 2021.08.03 |
|---|---|
| 이분 매칭(Bipartite Matching) (0) | 2021.08.02 |
| 위상 정렬(Topology Sort) (0) | 2021.08.02 |
| 플로이드 와샬 알고리즘 (Floyd Warshall Algorithm) (0) | 2021.07.31 |
| 에라토스테네스의 체 (0) | 2021.07.28 |