버블정렬은 옆에 있는 원소와 비교하여 더 작은 값을 계속해서 앞으로 보내는 것이다.
[수행1]
1 10 5 8 7 6 4 3 2 9 --> 1과 10을 비교하고 1이 더 작기 때문에 넘어간다.
1 10 5 8 7 6 4 3 2 9 --> 1 5 10 8 7 6 4 3 2 9 --> 10과 5를 비교하고 5가 더 작기 때문에 앞으로 옮긴다.
1 5 10 8 7 6 4 3 2 9 --> 1 5 8 10 7 6 4 3 2 9 --> 10과 8을 비교하고 8이 더 작기 때문에 앞으로 옮긴다.
1 5 8 10 7 6 4 3 2 9 --> 1 5 8 7 10 6 4 3 2 9 --> 10과 7을 비교하고 7이 더 작기 때문에 앞으로 옮긴다.
.
.
.
1 5 8 7 6 4 3 2 10 9 --> 1 5 8 7 6 4 3 2 9 10 --> 10과 9를 비교하고 9가 더 작기 때문에 앞으로 옮긴다.
[수행2]
위와 같은 방식으로 다시 반복하면 1 5 7 6 4 3 2 8 9 10 의 결과를 얻을 수 있다.
[수행3]
위와 같은 방식으로 다시 반복하면 1 5 6 4 3 2 7 8 9 10
=> 위 방식들을 반복적으로 수행하면 최종적으로 1 2 3 4 5 6 7 8 9 10 가 이루어진다.
[예제]
#include <stdio.h>
int main() {
int i, j, temp;
int array[10] = {1, 10, 5, 8, 7, 6, 4, 3, 2, 9};
for(i=0; i<10; i++) {
for(j=0; j<9-i; j++) {
if(array[j] > array[j+1]) {
temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
}
}
}
for(i=0; i<10; i++) {
printf("%d ", array[i]);
}
}<변수>
i, j : 배열에 있는 원소들을 반복적으로 탐색하기 위해 사용되는 변수
temp : 특정한 두 수를 서로 바꾸기 위해 사용되는 변수
for문을 통해 각 원소값의 비교를 수행한다. 두번째 반복문에서 9-i로 설정해준 이유는 뒤에서부터 집합의 크기를
하나씩 감소시키기 때문이다.
원소값 비교를 수행할 때 변수 temp를 활용하여 두 개의 원소값 위치를 바꿔준다.
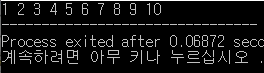
[결과]
[버블 정렬의 시간 복잡도]
버블 정렬의 시간 복잡도는 O(N^2) 이다.
버블 정렬은 한번 반복을 할 때마다 집합의 크기가 1씩 줄어든다. 즉, 이러한 과정을 표현하면 선택 정렬과 마찬가지로
10 + 9 + 8 + ... + 1 =55 이며, 10 * (10+1) / 2 와 같은 공식으로 풀 수 있다.
10 * (10 + 1) / 2 와 같은 공식을 수식으로 표현하면 N * (N+1) / 2 로 표현된다.
컴퓨터에서는 위와 같이 2로 나눈 값같은 경우에는 N이 굉장히 크다는 가정 하에 별 의미가 없기 때문에 간단하게
나누거나 더하는 연산들은 다 무시한다. 그렇기 때문에 수식을 쉽게 표현하면 N*N 이며,
시간 복잡도는 O(N^2)를 만족하는 것이다.
[소감]
버블 정렬과 선택 정렬의 시간 복잡도는 같지만 선택 정렬은 가장 작은 수를 탐색해 교체를 해주고
버블 정렬은 수행과정에서 매번 교체를 해줘야 한다는 점에서 수행 시간 측면에서
버블정렬이 선택정렬보다 더 비효율적이라는 것을 알 수 있었다.
출처
https://blog.naver.com/ndb796/221226803544
3. 버블 정렬(Bubble Sort)
지난 시간에는 가장 작은 값을 선택해서 앞으로 보내는 선택 정렬(Selection Sort) 알고리즘에 대해 알아...
blog.naver.com
'알고리즘 > 나동빈 실전 알고리즘' 카테고리의 다른 글
| 힙정렬(Heap Sort) (0) | 2021.07.20 |
|---|---|
| 병합정렬(Merge Sort) (0) | 2021.07.20 |
| 퀵정렬(Quick Sort) (0) | 2021.07.16 |
| 삽입정렬(Insertion Sort) (0) | 2021.07.16 |
| 선택정렬(Selection Sort) (0) | 2021.07.16 |